
intelligent patient data generator (iPDG)
(Wojtusiak, et al.,)
This project focuses on large scale generation of realistic synthetic patient data. Our mission is to go beyond what is often seen in synthetic data (i.e., demographics or claims), but be able to additionally generate clinical data and consumer-generated data. We use machine learning to learn models from real data, combine these models with expert knowledge, and together apply to generate new synthetic data.
Patient data is an important factor in managing a patient’s overall health and equips providers a bigger picture and better understanding of their patient. Patient data is also an essential tool in providing a better quality of care through preventative measures and addressing current medical conditions. However, patient data is also regarded as sensitive and protected information that is only available to those who have been given the privilege to access such information.
While many research projects in healthcare and medicine focus on analyzing de-identified and limited datasets, there are important applications that require data that is not limited. Some of the applications include:
EHR Software Testing – used in testing functionality of newly developed EHR systems
Algorithm Development – methods used in data mining, health services research, statistics, and other areas that rely on data that resemble real patient data.
Education – synthetic data is useful in training students in areas that require access to large amounts of realistic data
Simulation – this type of testing is usually done within the healthcare setting where training incorporates using a “dummy” patient, large scare discrete-event, and/or agent-based simulation used to model large populations of patients like the Monte Carlo simulation used to test decision-making modelsEpidemiology – the model’s accuracy depends on the use of accurate realistic data
The project’s two min goals are to create machine learning methods capable of effectively capturing longitudinal patient data, and by doing so to create a set of models that can be used to generate synthetic longitudinal data. Our goal is to be able to capture a variety of types of data present in health, healthcare, and medical domains:
Demographics – includes information that may or may not change such as: name, MRN, DOB, SSN, race, ethnicity, and place of birth
Family History – used as an additional factor as a part of the patient’s medical history which may or may not typically coded
Immunizations – availability of vaccinations including immunization guidelines on or during the patient’s lifespan considering that vaccinations and immunizations change over time
Diagnoses – play an essential role in providing the appropriate care and preventing associated comorbidities. Diagnoses may or may not be coded which can also be a part of the provider’s progress notes
Others including procedures, treatments, prescriptions or drugs, vitals, lab tests including lab results, physician orders, radiological tests and images, dental information, billing, survey, sensors, social media and genomic data, and other related patient assessments
How does it work?
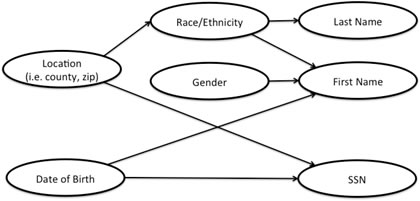
The approach we have taken in this project is to use machine learnign models to find patterns in real data and then use these patterns to generate new synthetic data. For demographics data we have uses statistics from US Census, US Center for Health Statistics, Social Security Administratin and other sources to create probabilistic models used to generate plausible data. The following plot illustrated interdependencies between selected demographics.
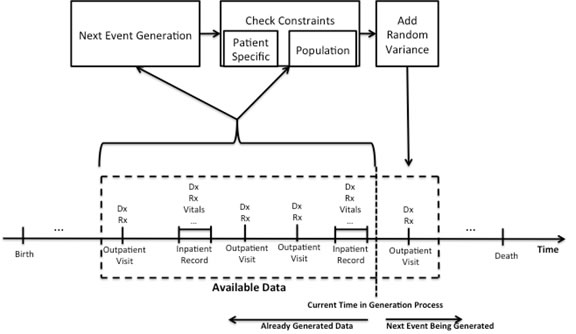
Longitudinal data is generated with time “sliding” through entire patient history. Learned modelsobserve patient history and infer most plausible next events (= some random variance).
Downloads
While the project is in the initial stages, we already generated some simple datasets.
– Demographics Set 1 (100 records)
– Demographics Set 2 (10K records)
– Demographics Set 3 (1M records)
Wiki page (team members only)